 同济大学主页
同济大学主页

近日,自主智能无人系统全国重点实验室操锟研究员作为第一作者,与新加坡南洋理工大学、瑞典皇家理工学院合作题为“A Differential Dynamic Programming Framework for Inverse Reinforcement Learning”的研究论文被机器人学顶级期刊IEEE Transactions on Robotics录用。该研究创新性地将微分动态规划方法引入逆强化学习领域,为从专家示例中自动学习代价函数、系统动力学与一般约束提供了高效、更具适用性的解决方案。
突破传统局限:微分动态规划赋能梯度高效计算
不同于传统微分动态规划方法仅被用于求解正向问题,操锟团队提出将其复用至逆向问题,构建增广系统模型与解析梯度计算机制,显著提升了求解效率。研究表明,与当前最先进方法相比,该框架在多项机器人任务中速度提升最高达1倍。
提出闭环损失函数,显著贴近真实数据生成场景
研究进一步提出新型闭环损失函数,直接匹配专家与智能体之间的反馈策略而非轨迹本身,以刻画更符合实际场景设定中的闭环特性。相比传统开环损失函数,该损失函数在大量仿真实验与无人机、无人车等真实实验中显示出显著优势。
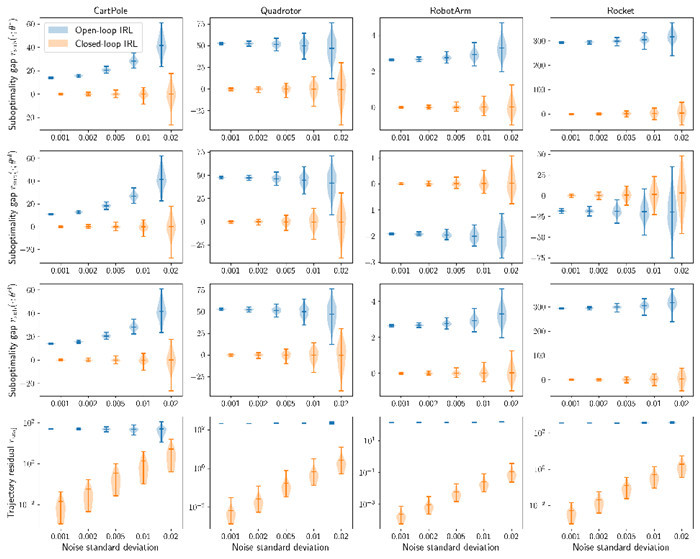
图1:开环与闭环逆强化学习算法输出在不同指标上的性能评估
该成果为智能系统自主学习与决策优化提供了方法论创新,是“AI for Engineering”的一个典型成功案例,为人工智能技术在自主系统、智能交通、能源互联网、智能医疗等领域的应用提供了坚实的理论支撑与算法基础。未来,团队将进一步探索该框架在多智能体系统、随机系统与人机协作中的扩展,并结合深度学习技术构建更具通用性的学习框架。
合作作者:Xinhang Xu(南洋理工大学),Karl H. Johansson(皇家理工学院),Lihua Xie(南洋理工大学)
本项目受到国家自然科学基金基础科学中心,上海市人工智能市级科技重大专项等基金的资助。
